|
GPU服务器多人共享使用时,往往会相互干扰影响,为了能使多人之间互不干扰,可以使用基于docker+MPS(Multiple Process Service)的方式共享使用GPU。 1. 需要在机器上提前安装好以下环境- 安装 docker;
- 安装NVidia 显卡驱动、CUDA、CUDNN,可以参照如下文章:
[color=inherit !important]NVIDIA显卡驱动,CUDA,CUDNN安装流程 - jimchen1218 - 博客园 (cnblogs.com[url]www.cnblogs.com/jimchen1218/p/14452417.html[/url]
如果机器可以运行GPU版本的Tensorflow,说明GPU的环境已经安装好了。
2. 安装NVidia-docker2安装nvidia-container-runtime,如果安装nvidia-docker2的话 添加package repositories - curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | sudo apt-key add -
- distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
- curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
- sudo apt-get update
- sudo sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-runtime.list
- sudo apt-get update
- sudo apt-get install nvidia-container-runtime
运行以下命令验证是否安装成功: sudo nvidia-docker run --rm nvidia/cuda:11.0-devel nvidia-smi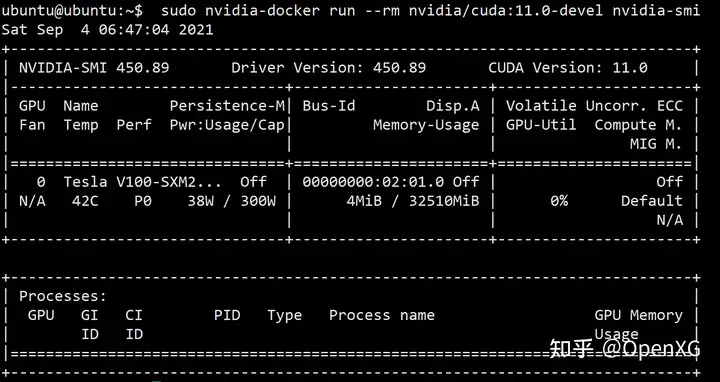
3. 运行tensorflow-GPU docker版sudo docker run --runtime=nvidia -it --rm -v ~/Workspace/tfexamples/:/mnt tensorflow/tensorflow:latest-gpu python /mnt/test.py
--runtime=nvidia, 指明使用GPU环境,安装Nvidia-docker2的话,使用该参数;如果是Nvidia-docker1,使用--gpus all
-v ~/Workspace/tfexamples/:/mnt,将host主机目录映射到docker中
tensorflow/tensorflow:latest-gpu,使用tensorflow gpu 镜像;
python /mnt/test.py,指定运行的脚本或程序
4. 共享GPU方式的运行Docker Tensorflow共享GPU需要首先启动MPS服务: export CUDA_VISIBLE_DEVICES=0 export CUDA_MPS_PIPE_DIRECTORY=/tmp/nvidia-mps export CUDA_MPS_LOG_DIRECTORY=/tmp/nvidia-log nvidia-cuda-mps-control -d
运行Docker Tensorflow-GPU sudo docker run --runtime=nvidia --ipc=host -it --rm -v ~/Workspace/tfexamples/:/mnt tensorflow/tensorflow:latest-gpu python /mnt/test.py
--ipc=host, 指明GPU的使用连接至本机的Nvidia-docker,共享GPU
关闭MPS服务:
echo quit | nvidia-cuda-mps-control
| 






 发表于 2023-6-22 21:54:02
发表于 2023-6-22 21:54:02

 收藏
收藏